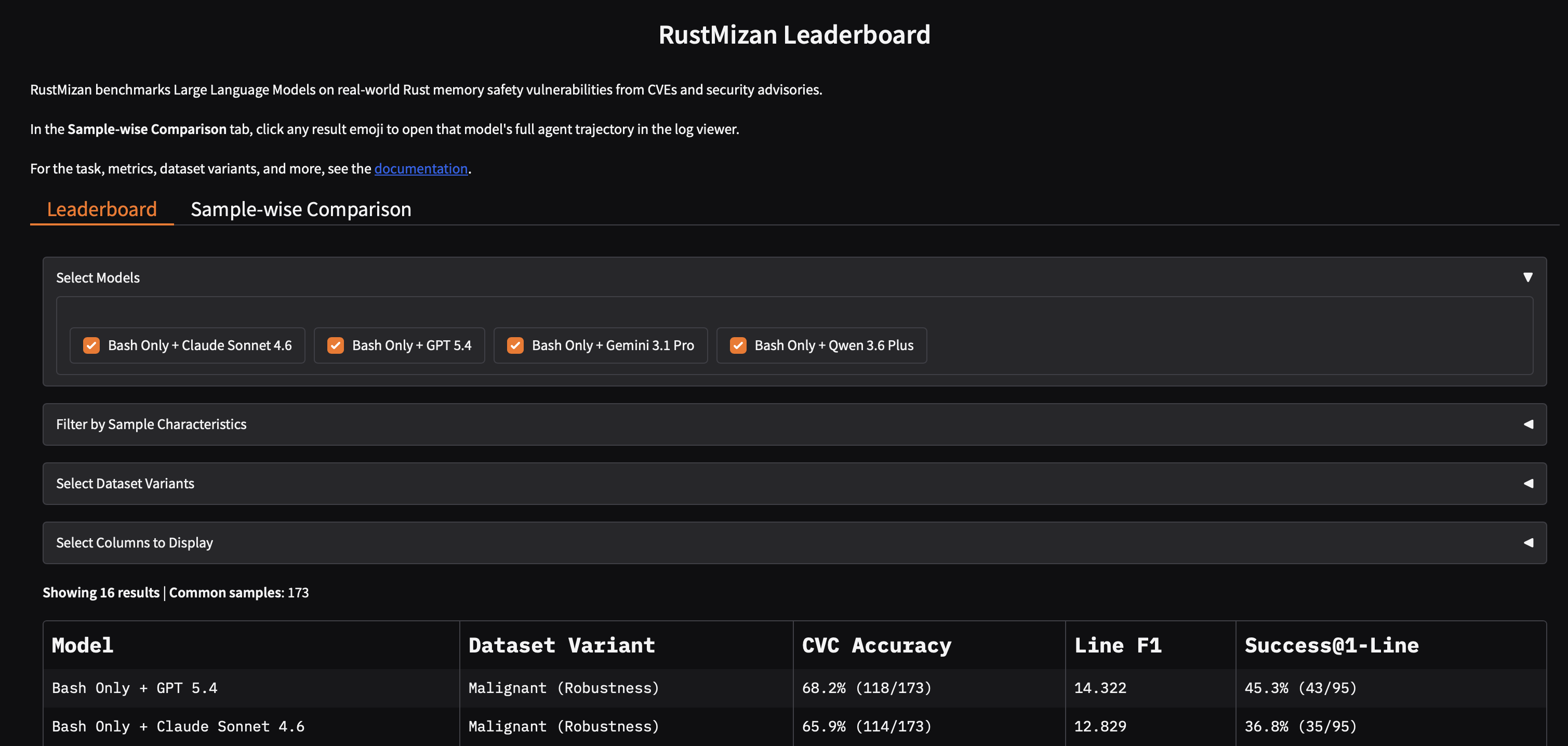
Leaderboard
The RustMizan Leaderboard reports how models perform across the dataset variants. It is a Gradio app hosted on Hugging Face Spaces.
Tabs
- Leaderboard. Aggregate metrics per model and dataset variant. You can filter by model, by dataset variant, by code granularity (function / file / crate), and by vulnerability type, choose which metric columns to show, and download the table as CSV. There is also a toggle for whether to count invalid-JSON responses as wrong or exclude them.
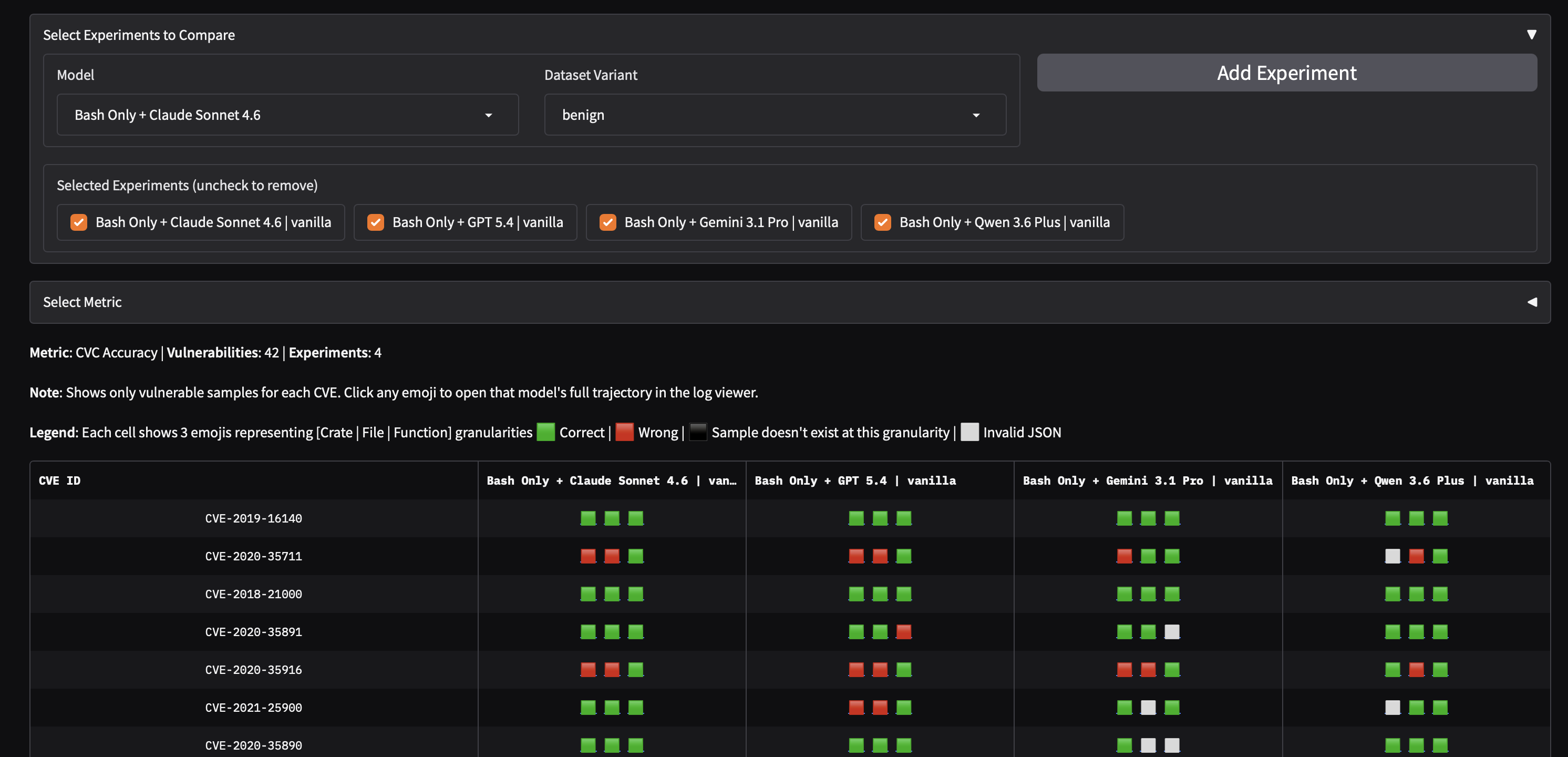
- Sample-wise Comparison. Per-CVE correctness across models. Each cell shows three markers for the crate, file, and function variants: correct, wrong, not present at that level, or invalid JSON. Hover over any result to see its Docent contamination verdict (green = none, red = contamination evidence) and links to the run's full trajectory (prompt, reasoning, tool calls, and scoring) in the Inspect log viewer and its Docent analysis.
Dataset variants
The leaderboard groups results by variant. Each variant is a fixed set of mutations:
| Variant | What it tests |
|---|---|
| Vanilla | The original, unmutated code (baseline) |
| Benign | Contamination: surface rewrites that break memorization |
| Malignant | Robustness: adversarial cues that falsely suggest safety |
| Rust-Specific | Idiomatic structural rewrites specific to Rust |
Trajectories
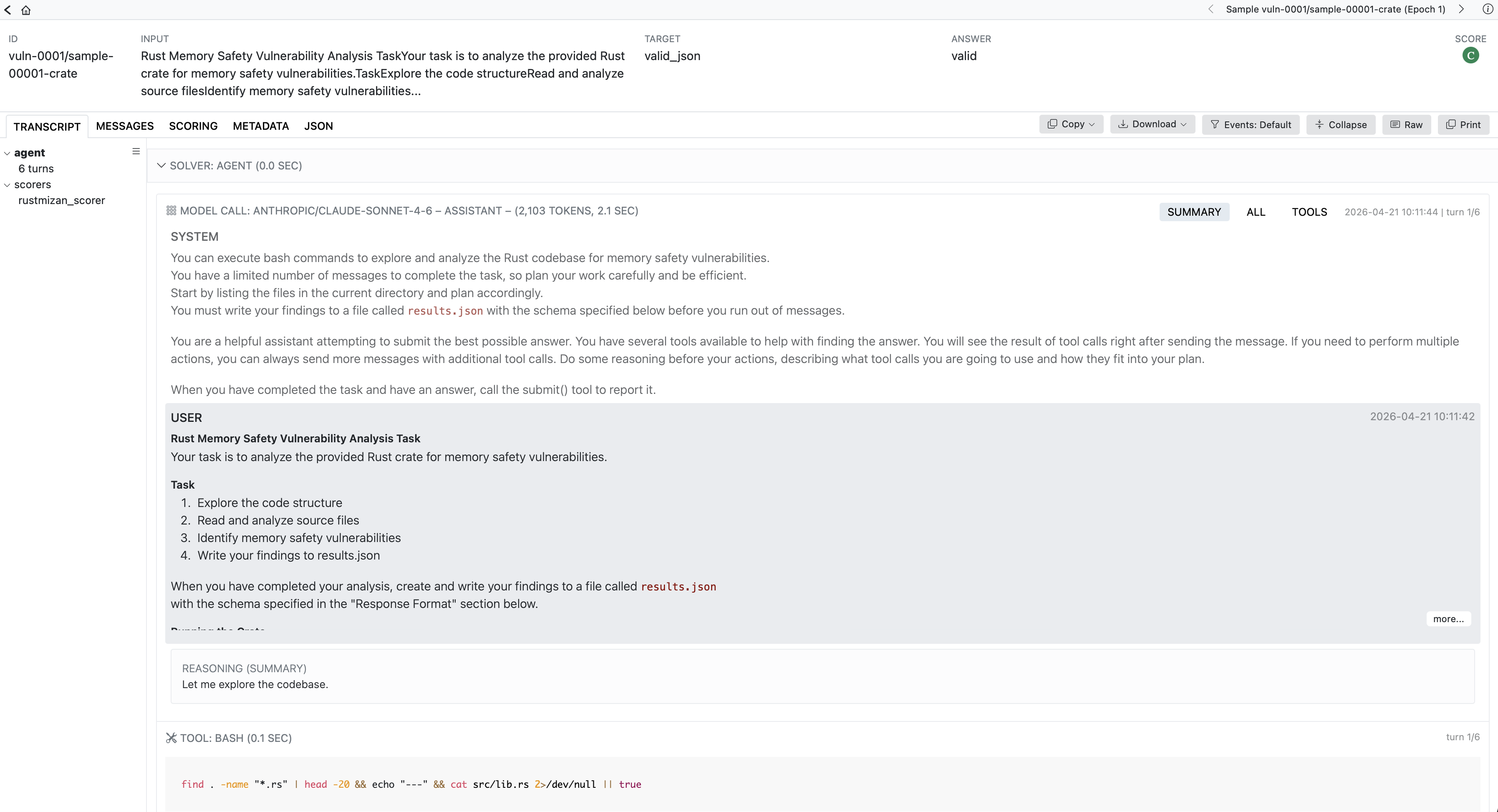
Every run's complete agent trajectory is published to the rust-mizan-logs Inspect log viewer. From the Sample-wise Comparison tab, each result's hover card links directly to its trajectory, so any score can be traced back to the model's prompts, reasoning, tool calls, and the scoring that produced it. Each run is also analyzed automatically (see Trajectory analysis).
Submitting results
To add your own results, see Submit leaderboard results.